
基于人工智能的全链路异常监控与自动化自愈平台实践
基于人工智能的全链路异常监控与自动化自愈平台实践
前言
随着分布式系统规模不断扩大,传统监控方式已难以满足海量日志数据实时处理与异常检测的需求。人工干预不仅效率低下,还容易延误故障处理。为此,引入人工智能技术,实现全链路的日志异常监控和自动化自愈策略,成为提高系统稳定性和降低运维成本的重要手段。本文将详细介绍如何构建这样一个平台,包括整体架构设计、各个模块的实现细节以及在实际操作中应注意的问题和改进方向。
系统架构设计
整个系统主要由以下几个模块组成:
日志采集层
部署在各服务节点上的日志采集 Agent(如 Filebeat 或 Fluentd),负责实时读取并标准化日志数据。数据传输层
利用 Kafka 或 RabbitMQ 构建高可靠性的消息队列,实现日志数据的异步传输,保证数据的高吞吐和容错性。存储与可视化层
使用 Elasticsearch 作为日志存储引擎,配合 Kibana 或 Grafana 实现日志检索、数据分析与可视化展示。实时处理与 AI 异常检测层
集成 Spark Streaming 或 Flink 对日志流进行实时处理,同时通过机器学习或统计模型对异常进行检测,形成预警。自动化自愈层
在检测到异常后,自动触发运维任务(如重启服务、扩缩容、故障切换),并通过 CI/CD 工具或 Kubernetes API 完成自愈操作。
下图为系统架构示意图:
[服务节点]
│
▼ Filebeat/Fluentd(日志采集)
[Kafka/RabbitMQ] —— 异步传输日志数据 ——► [Elasticsearch] ——► 可视化展示(Kibana/Grafana)
│
▼
[Spark Streaming/Flink]
│
▼
AI 异常检测模块
│
▼
自动化自愈与告警系统(Jenkins/Ansible/K8s API)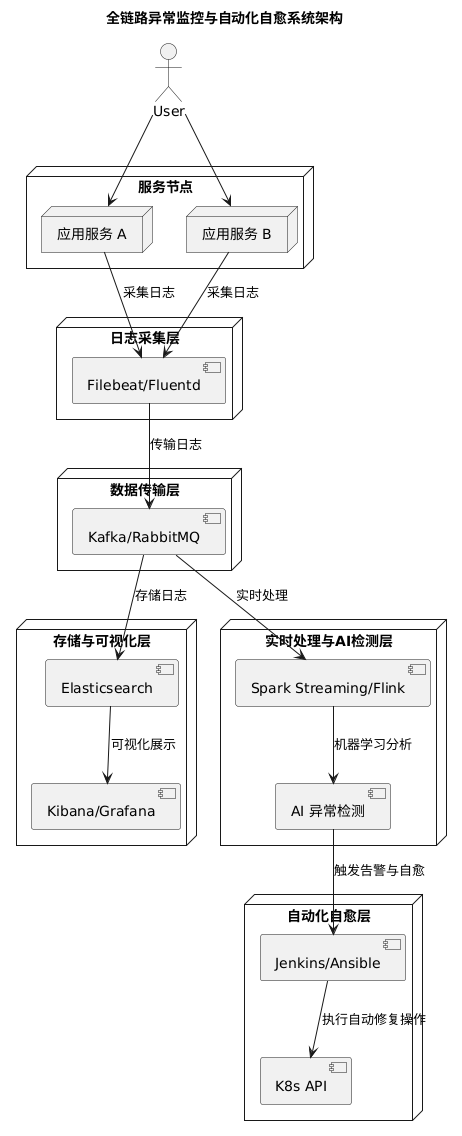
具体实现步骤
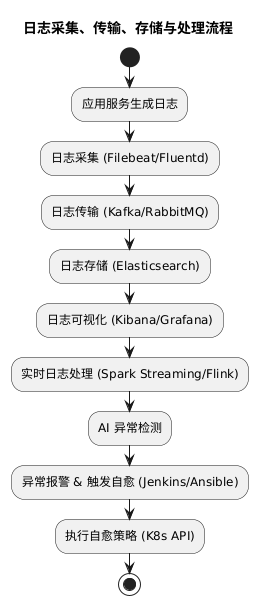
1. 日志采集与传输
a. 部署日志采集 Agent
选型推荐:使用 Filebeat(轻量、易配置)
安装与配置:
在每个服务节点安装 Filebeat(例如使用包管理器安装或 Docker 部署)。
编辑
filebeat.yml配置文件,指定日志文件路径和 Kafka 输出。启动 Filebeat,并验证日志是否正确推送到 Kafka。
filebeat.inputs: - type: log enabled: true paths: - /var/log/myapp/*.log output.kafka: hosts: ["kafka1:9092", "kafka2:9092"] topic: "logs_topic"
b. 部署 Kafka 消息队列
安装与集群配置:搭建 Kafka 集群,建议至少 3 个节点以保证高可用性。
创建 Topic:创建一个专用于日志传输的 Topic,配置合适的分区数量(例如根据日志量设定 10 个分区)。
消费者组:下游日志处理模块通过消费者组来消费日志数据,实现负载均衡与容错。
2. 日志存储与可视化
a. 部署 Elasticsearch 集群
集群部署:可使用 Docker Compose 或 Kubernetes 部署 Elasticsearch 集群,建议配置 3 个或更多节点。
日志接入:利用 Logstash 或直接使用 Kafka 消费者将日志数据写入 Elasticsearch。可以设计索引策略,如按日期创建索引以提高查询效率。
b. 搭建可视化平台
Kibana 或 Grafana:安装并配置 Kibana(或 Grafana 配合 Elasticsearch 插件),创建仪表板展示关键指标(错误率、响应时间、流量变化等)。
3. 实时处理与 AI 异常检测
a. 部署流处理引擎
选型推荐:Spark Streaming 或 Flink,根据团队熟悉度进行选择。
数据清洗:编写流处理程序,消费 Kafka 中的日志数据,对数据进行格式转换、去重、合并等预处理操作。
b. 构建异常检测模型
规则匹配:实现基于预设阈值的简单报警规则,例如短时间内错误日志数量超过设定值时触发报警。
统计方法:采用移动平均、标准差等方法检测指标异常。
机器学习模型:利用历史日志数据训练异常检测模型(如基于 LSTM 的时序预测),不断通过反馈机制对模型进行自适应调优。
实现建议:可以使用 Python 的 scikit-learn 或 TensorFlow/Keras 搭建模型,并通过 Spark 的 MLlib 进行在线预测。
4. 自动化自愈策略

a. 定义自愈策略
自动重启:当某个服务出现异常时,自动调用脚本或 Kubernetes API 重启容器或 Pod。
扩缩容:根据流量和负载自动调整服务实例数量,利用 Kubernetes 的自动扩缩容机制实现动态调整。
故障切换:在检测到节点故障时,自动将流量切换到备用节点,保证服务不中断。
b. 集成运维工具
CI/CD 对接:利用 Jenkins 或 GitLab CI 部署自动化运维任务,当异常检测模块触发事件时,自动启动对应任务。
自动化脚本:编写 Ansible 或 Shell 脚本,处理常见问题(例如清理缓存、重启服务)。
安全审计:所有自动操作均需记录日志,并设置审核与回滚机制,避免误操作带来更大风险。
5. 部署与测试
a. 开发环境搭建
使用 Docker Compose 将 Filebeat、Kafka、Elasticsearch、Logstash、Spark Streaming 等容器化部署在本地进行测试。
编写简单的测试脚本,模拟日志产生并验证整个流程的正确性。
b. 生产环境部署
利用 Kubernetes 将各个模块部署成独立的服务,采用 Helm Charts 简化部署流程。
监控各服务状态,调优 Kafka、Elasticsearch 的参数以应对实际负载。
c. 性能调优与故障演练
通过 Grafana 实时监控系统各指标,查找瓶颈并进行优化。
进行故障模拟(例如人工关闭某个节点)测试自动自愈策略的效果,确保系统在异常情况下能快速恢复。
实践中的挑战与经验总结
在实际构建过程中,你可能会遇到以下挑战:
数据延迟与一致性:分布式系统中,日志数据从采集到最终存储可能存在一定延迟;需要合理设计数据缓冲和批处理机制。
模型准确率:初期采用规则匹配或简单统计方法可能存在误报或漏报,利用机器学习方法需要大量历史数据和持续的模型调优。
自动化风险控制:自动化自愈操作必须非常谨慎,确保不会因误操作导致系统更大范围的故障,因此建立完善的审核和回滚机制至关重要。
资源调度与扩展:高并发日志数据对 Kafka 和 Elasticsearch 的性能提出挑战,必须合理规划集群规模和资源调度策略。
通过不断测试、调优和实践,整个系统将逐步趋于成熟,为大规模分布式系统提供高效的全链路监控和自动化自愈能力。
总结
详细介绍了如何构建一个基于人工智能的全链路异常监控与自动化自愈平台,从日志采集、数据传输、存储、实时处理、AI 异常检测到自动化自愈策略,各个环节均给出了具体实现方案和操作步骤。实践过程中虽然会遇到数据延迟、模型精度和自动化风险等问题,但通过持续调优和完善审核机制,这套系统将为分布式系统的稳定运行提供坚实保障。
实践建议
从小规模开始:建议先在测试环境中搭建一个简化版的系统,逐步验证各模块的功能,再扩展到生产环境。
重视日志数据质量:日志格式标准化和数据预处理是整个系统的基础,务必保证日志数据的准确性和一致性。
持续模型调优:利用历史数据不断训练和更新异常检测模型,结合人工反馈不断优化算法。
完善自动化运维流程:在实现自动化自愈时,一定要配置好报警、日志记录、审核和回滚机制,确保安全可靠。
写在最后
浩渺云海间,缘分如丝牵,若您为网站之精髓所动,可于下方订阅之卷,或诸平台觅得契合之径,唯需寄一封电邮之名,便与吾辈缔结灵犀,共享智慧之光,永续共鸣。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
